Getting started with Python for data analysis.
Dataframes are 2-dimensional labeled data structures with columns of potentially different types. You can think of it like a spreadsheet. Numpy and Pandas are two very powerful and commonly used libraries used for datasets in bioinformatics. If you don’t have these installed, you can get them as part of the SciPy bundle. You can also use conda to install them individually.
Numpy
Numpy is a library for arrays.
- Helpful, lengthy explanation of indexes and slices in arrays: https://stackoverflow.com/a/24713353
- Numpy basics: https://docs.scipy.org/doc/numpy-1.15.0/user/quickstart.html
- More explanation of data types (numpy): https://docs.scipy.org/doc/numpy-1.15.0/user/basics.types.html
- Why do we want to use numpy vs regular python lists? https://stackoverflow.com/questions/993984/what-are-the-advantages-of-numpy-over-regular-python-lists
Pandas
Pandas is a python library for data frames. Understanding the basics of numpy will be helpful before getting into pandas.
- Pandas introduction: http://pandas.pydata.org/pandas-docs/stable/10min.html
- And another: https://www.learnpython.org/en/Pandas_Basics
- Selecting data in a dataframe (iloc): https://www.shanelynn.ie/select-pandas-dataframe-rows-and-columns-using-iloc-loc-and-ix/
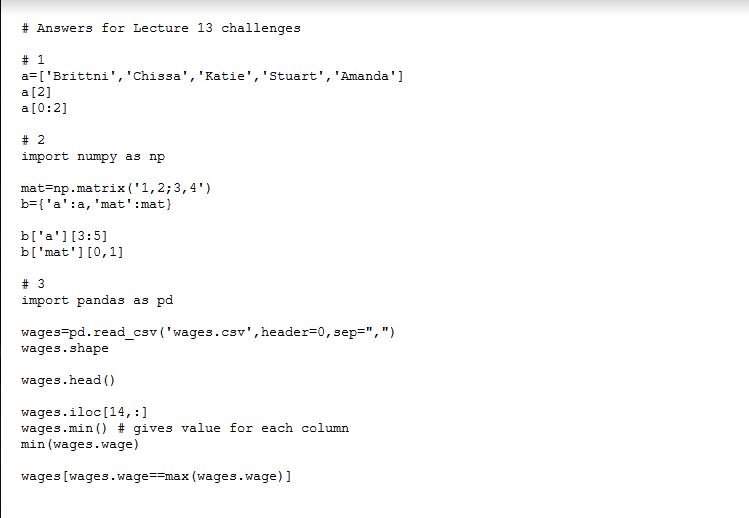
Tutorial challenge from an introduction to biocomputing class - Prompt and corresponding code
To follow along you can download the dataset by pasting this code into your command line:
curl -L https://osf.io/kges5/download -o wages.csv